Why pretraining runs fail
The model just learns the trivial solution of copying the answer from the output, and the gradient carries no useful signal.
You split the tokens across experts by which tokens each expert most strongly prefers, so every expert ends up with roughly the same number of tokens.
But which expert token gets allocated to can depend on which expert token might be routed to.
Experts ignore the tokens in their batch that rank weakly for them, in order to avoid overflowing their padding budget.
This breaks causality because a later token being more strongly matched to an expert can cause an earlier token to be dropped.
Variance can average out, but bias compounds.
- Llama 4: expert choice
- Gemini 2 Pro: token dropping
- GPT-4: swamping by accumulator (FP16 collectives losing small gradients to a large running sum)
Collectives
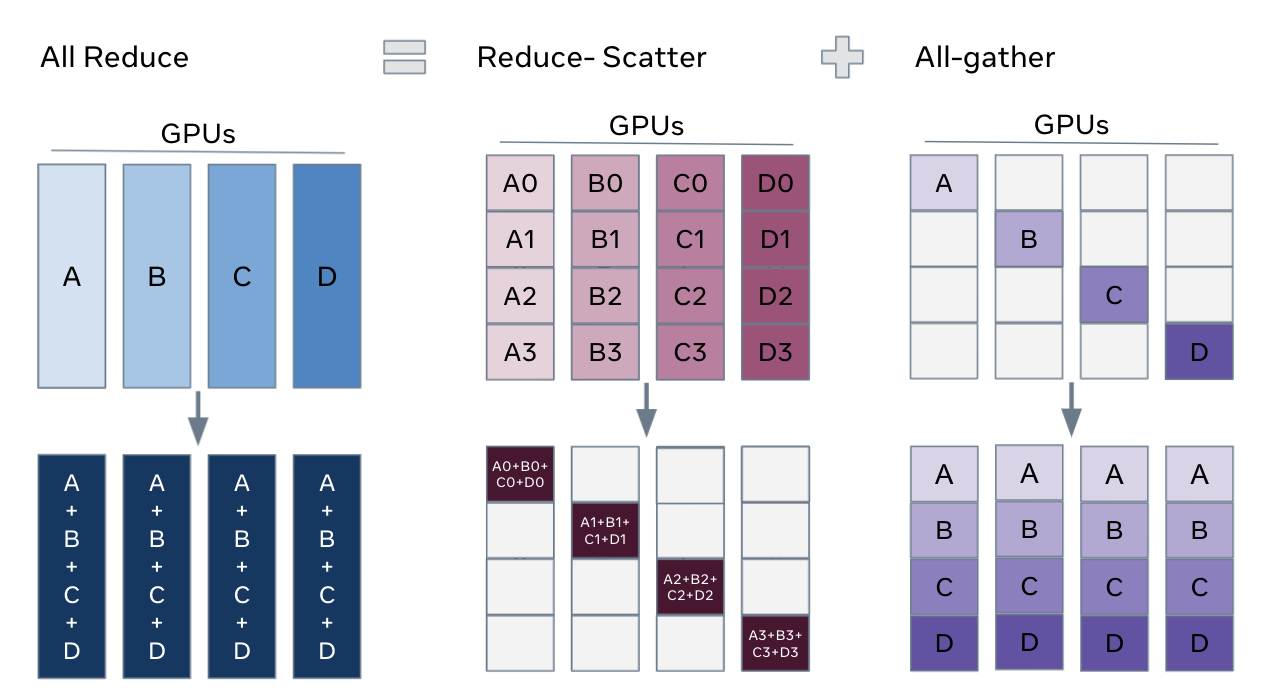
Every GPU starts with a different shard. Afterwards, every GPU has the full concatenated result.
Each GPU ends up with the element-wise reduction (i.e. sum) across every GPU.
Each GPU ends up with its shard of the element-wise reduced result.
Strictly cheaper than all-reduce because you skip the final all-gather.
Each GPU starts with of info. It needs to send of that to each of the other GPUs.
Parallelisms
Each GPU only has a limited amount of HBM — a B300 is 288 GB — and this is not enough to store the weights as models get bigger, much less their activations.
Each GPU stores only of the parameters of each layer. Before processing a layer, you all-gather the full layer's parameters from all the GPUs. After processing, each GPU discards the gathered parameters.
The only thing being communicated is the weights, which don't depend on what happened in the layer before, so you can start all-gathering the next layer while still computing the current one.
Tensor and expert parallelism, by contrast, must share activations for one layer before processing the next.
In regular DP, you still need an all-reduce after every layer of the backward pass to sync the batch's gradients across all GPUs. That all-reduce has comms volume .
FSDP adds all-gathers — one per layer in the forward pass, one per layer in the backward pass. But an all-gather is half the comms volume of an all-reduce. So naive FSDP comms volume ends up being (all-gather forward and back, plus all-reduce on back).
You can do even better: since each gradient shard only needs to end up on the one GPU that owns it, replace the all-reduce with a reduce-scatter (which skips the final broadcast step). That gets you to total — a 50% overhead over vanilla DP.
Compute time decreases as you add more GPUs, but comms time does not.
The batch size beyond which doubling the batch stops halving the number of steps to reach a target loss.
FSDP is data-parallel, so each GPU processes at least one sequence. Attention is computed within a sequence and can't (easily) be split across GPUs.
At the beginning of the batch, the GPUs dedicated to the final layers aren't being used; at the end of the batch, the GPUs dedicated to the first layers aren't being used.
You can't overlap batches to fix this because you need to consolidate gradients and update the model before processing the next batch.